Prompt injection as a solution to make agents reliable
tl;dr
- AI agents are unreliable, especially in production due to unpredictable behavior across diverse inputs.
- Instead of bloating system prompts with countless edge cases, we developed "intentional prompt injection" - dynamically injecting relevant instructions at runtime based on semantic matching.
- This technique primes the LLM to focus on the relevant information to improve it's accuracy and consistency.
- Dynamic prompts helps avoid "prompt debt", keeping your static prompts maintainable.
(For the rest of the article, we assume you're already familiar with the basics of LLM-based agents.)
intro
You know the deal: going 0-to-demo with an AI agent is easy, but going from demo-to-production is really hard. Real-world problems demand predictable and consistent behavior, which many agents (except for the most primitive) can't deliver.
For example, if a user asks an AI customer service bot to "cancel my order ABC", the agent should enact the CANCEL_PENDING_ORDER tool with the order id ABC, and other necessary information (assuming it gathered it earlier in the session). Also, you would expect the same user request combined with the same session context produces the exact same tool call. But in practice, programming the LLM-based agent to reliably perform the correct action is quite difficult. Benchmarks like τ-bench demonstrate that even state-of-the-art LLMs struggle with reliability when tasks repeat.
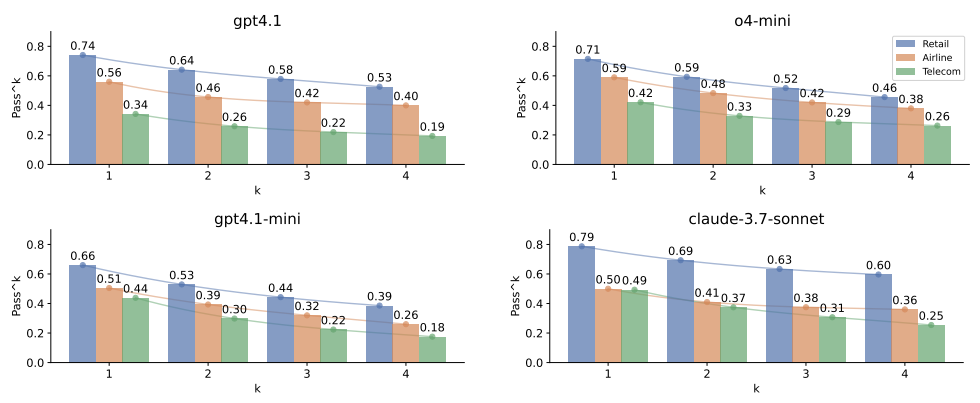
(k refers to the number of trials run per individual task.)
This is a big reason why 95% of GenAI pilots are failing.
Some of this error is irreducible because of the non-determinism of LLMs. However, a major reason why agents often struggle in production settings is because of the open-ended input space. A lot of agents, especially user-facing ones, are confronted with a practically infinite range of different possible inputs. Back to the customer support agent for retail: In the embryo phase of development, you're usually evaluating the agent against a comparatively simple set of cases, like "Can you cancel order A1B2C3?" or "What is your return policy?". But once you deploy, the agent gets exposed to all sorts of complex cases, e.g.
"Cancel every item in my order last week that's not related to video gaming, and split the refund between my credit card and paypal account."
There are emerging design principles to help make agents resilient to the complexity of the real world (12-factor agents is one of my favorites). These are a gift. But creating modular agents, and limiting tool use, etc. doesn't obviate the need to wrangle LLM prompts--a frustrating process with a lot of trial and error. There's no way around it. A system prompt may start off like this:
You are a retail customer support agent who can help users cancel or modify pending orders, return or exchange delivered orders, modify their default user address, or provide information about their own profile, orders, and related products.
And you start appending all sorts of rules, conditions, and exceptions, to get the agent to behave the way you want:
You are a retail customer support agent who can help users cancel or modify pending orders, return or exchange delivered orders, modify their default user address, or provide information about their own profile, orders, and related products.
...
NEVER claim to be human or use phrases like "I understand how frustrating that must be for you"
...
Returns must be within 30 days with original packaging
NO returns on: underwear, swimwear, personalized items, opened electronics, perishables
...
NEVER use ALL CAPS (appears angry)
...
CRITICAL: When uncertain about ANY situation, escalate rather than guess. Customer retention is more important than chat resolution metrics.
This works well--not perfect. But the outcome of this production-hardening process is a "franken-prompt" that's brittle to updates, hard to maintain, and confusing (both for humans and LLMs). To achieve better reliability without adding "tech debt" to prompts, we developed an alternative approach to prompt optimization, one that attempts to keep the main prompt lean and comprehensive, while handling edge cases in a dynamic way.
motivating example
We'll use the example of an AI customer support agent for a hypothetical airline (taken from τ-bench). The agent's task is to help a customer update their flight reservation: Change the listed passenger to themselves, upgrade to economy class, and add 3 checked bags (Task 4 from τ-bench). The agent is primed with a meticulously crafted system prompt and an array of tools, including update_reservation_flights, update_reservation_passengers, and update_reservation_baggages.
When we run this scenario (whether a human was acting as the customer or we were simulating the customer with another LLM), we found that the agent would not update the passenger on the reservation about 20% of the time (roughly 1 out of 5 simulations of the scenario). This was puzzling because the agent does have explicit rules in the system prompt about updating passenger information:
- Change passengers: The user can modify passengers but cannot modify the number of passengers. This is something that even a human agent cannot assist with.
We tried tweaking the language for this bullet, and upper casing for emphasis, and including modifiers like CRITICAL and IMPORTANT. Didn't really help. But this wasn't an exhaustive search. We wanted to try something that wouldn't inadvertently cause the model to overlook other instructions embedded in the system prompt. We wanted to try something more sustainable.
intentional prompt injection
We assembled such cases into a list of key-value pairs, where the key (query) is some textual trigger in the user's response, and the value (rule) corresponds to instructions the agent must obey. For example,
How do we make use of this? At runtime, the idea is to dynamically check the user's message against the queries for a match, and if there's a match, then we "inject" the mapped instructions into the content of the message before piping it into the LLM's context. So an augmented user message might look like this:
For the example from the last section, this helped us achieve near-perfect reliability. In repeated runs of the same scenario, the LLM-based agent would always pass (i.e. perform the expected set of actions). We suspect it's because we're taking advantage of the model's recency bias in observing context, which has the effect of priming it with the most relevant policy rules from it's system prompt when responding. Basically, we're assisting the model with the task of recall from it's own context.
benchmarks
We did run a few experiments to check the robustness of this technique, but our methodology shouldn't be taken as scientific. We used τ-bench, which includes 50 different scenarios for the airline customer support domain. Some basic experiment configuration:
- We selected the first 6 scenarios for testing.
- We used GPT-5 to power the AI agent, and Claude 4 Sonnet to power the user simulator.
The first 4 scenarios have nothing to do with modifying passenger information on existing reservations. Here's a sample of the user prompt for the second scenario:
Your user id is omar_davis_3817, you just faced some money issue and want to downgrade all business flights to economy, without changing the flights or passengers. You are fine with refunding to original payment for each reservation. You want to know how much money you have saved in total. You are emotional and a bit angry, but you are willing to cooperate with the agent.
For the first 4 scenarios, we ran 5 trials for the control (no prompt injection) and 5 trials with the prompt injection. GPT-5 breezed right through:
| Scenario | Baseline Pass Rate | Prompt Injection Pass Rate |
|---|---|---|
| 0 | 100% | 100% |
| 1 | 100% | 100% |
| 2 | 100% | 100% |
| 3 | 100% | 100% |
| 4 | ||
| 5 |
Scenario 4 corresponds to the motivating example from the preceding section, which alerted us to the issue in the first place. It's also the example that helped us formulate the prompt injection technique. Scenario 5 is a similar scenario, where the user is requesting a change in passenger information (to themselves), but wasn't used for any development. Here are the results for those two scenarios, where we ran 10 trials per scenario per group:
| Scenario | Baseline Pass Rate | Prompt Injection Pass Rate |
|---|---|---|
| 0 | 100% | 100% |
| 1 | 100% | 100% |
| 2 | 100% | 100% |
| 3 | 100% | 100% |
| 4 | 80% | 100% |
| 5 | 80% | 100% |
The agent solved 8 of the 10 attempts for both scenario 4 and 5. When strapped with the prompt injection mechanism, it didn't face any issues. It's no surprise that the dynamic prompting helps with reliability.
We used semantic similarity to match the user's message to the special list of query-rule pairs we crafted. We tuned the similarity threshold to make sure we only inject the prompt when the user's message is very similar to the query. Despite the higher threshold, we still found that prompt injection would fire for unrelated user messages but in those cases, the extra instructions didn't hurt.
what about few-shot
Few-shot prompting, i.e. inserting examples of scenarios into the system prompt, did help with reliability, but not when the session between the user and the agent were orthogonal to any of the examples. Also, because we're dealing with long conversational exchanges, the examples were too sparse to be effective, and they needlessly bloated input token counts. We decided it just wasn't a generalizable solution.
final thoughts
The broader insight behind this method is intriguing: Dynamically engineered prompts that elicit correct and consistent behavior out of LLM-powered agents. We believe we're just scratching the surface here. Now for many applications, a static system prompt will suffice. But for more complex use cases, a single, monolithic prompt might be too rigid. It could work at the beginning, but as the application grows and matures, a single container will accumulate "prompt debt", becoming a steaming pile of edge-case handling (like a very long switch statement). This runtime retrieval technique offers a more scalable solution.
If you're building AI agents and want to ensure reliable, policy-compliant behavior, give intentional prompt injection a try. Feel free to reach out to us if you are looking for help at hello@controlpla.in.
Note: if you're interested in running benchmarks for agents, there's a new version of τ-bench, called τ²-bench. It's slightly more complex so we didn't use it for our experiments, but it's the latest version of this benchmark which is actively maintained.